|
|||||||||||||||
|
|||||||||||||||
Règles de traitement pour les étiquettes RDF d'ICRAIntroductionLe système ICRA permet aux fournisseurs d'étiqueter leur contenu rapidement et efficacement, tout en offrant une grande flexibilité. Pour pouvoir garantir des résultats prévisibles aux utilisateurs, la façon dont les différents filtres traitent les étiquettes doit être la même pour tous. Les règles de traitement recommandées sont indiquées ci-dessous pour permettre aux fournisseurs de contenus d'évaluer quelle est la méthode la plus appropriée à l'étiquetage de leur propre contenu1.1 Un module de référence et des informations techniques plus détaillées sont également disponibles pour les fabricants de filtres. Ils expliquent entre autres comment les données d'auto-étiquetage peuvent être utilisées avec les sources de données de tierces personnes. Pour une ressource donnée (une page, une image, etc.), il existe trois sources d'étiquette possibles :2.
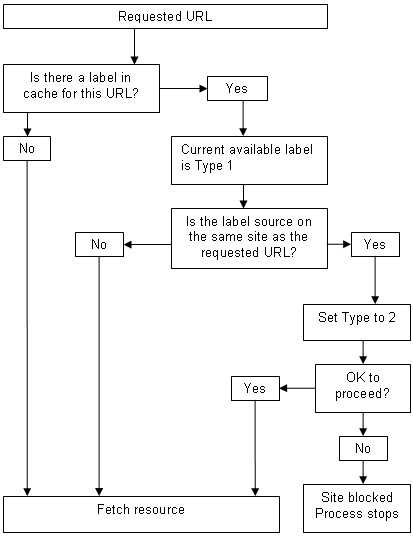
Comme détaillé ci-dessous, les filtres DEVRAIENT attribuer des priorités grandissantes à chacune de ces sources. Avant de récupérer la ressource
Si le filtre possède déjà une étiquette pour l'URL requise dans sa mémoire cache, une étiquette de Type 1 est immédiatement disponible. Si cette étiquette a été au départ récupérée sur le même site que l'URL qui nous intéresse maintenant, l'étiquette DEVRAIT être considérée comme de Type 2. Si les données de l'étiquette dans la mémoire cache ont été récupérées à partir d'un site Web différent, elle reste de Type 1 ; la ressource doit être extraite et ses données doivent être contrôlées. En bref :
Ceci peut s'expliquer de plusieurs façons, mais en gros, l'idée est que les étiquettes reliées à partir d'une ressource sont « plus près » du fournisseur de contenu que les étiquettes qui auraient pu être publiées par une personne ayant un loin étroit ou aucun lien du tout avec le contenu décrit. Ce point est développé dans le paragraphe suivant, où une priorité encore plus importante est donnée aux étiquettes qui sont reliées à partir de la ressource elle-même. Il ne faut pas confondre les étiquettes de Type 1 avec l'étiquetage d'une tierce personne. Si un filtre est configuré pour demander des étiquettes à partir d'une source d'une tierce personne, comme une base de données en ligne ou un analyseur de contenu, le filtre traitera ces données séparément. Les étiquettes de Type 2 ont la priorité sur les étiquettes de Type 1, uniquement dans le contexte de l'auto-étiquetage. S'il n'y a aucune donnée dans la mémoire cache du filtre, la ressource qui se trouve à l'URL DOIT être extraite.
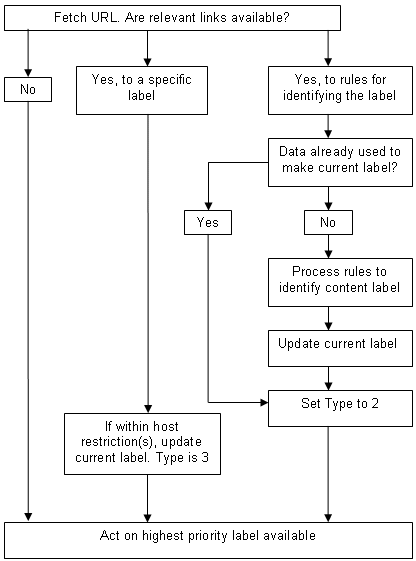
Identification de l'étiquette appropriéeSi la ressource inclut des liens vers des données sur l'étiquette, il peut être nécessaire de l'extraire et de la traiter. (N'oubliez pas que les étiquettes sont toujours conservées séparément, et jamais dans la ressource elle-même.) Si la ressource inclut un lien vers une étiquette spécifique, celle-ci est classée comme Type 3. Puisqu'il s'agit de la plus haute priorité dans la hiérarchie, une fois qu'une étiquette de Type 3 est disponible, aucun autre traitement n'est nécessaire pour identifier l'étiquette appropriée à utiliser pour cette ressource. Cependant, les clients DEVRAIENT vérifier les restrictions d'hôtes. Il est évident qu'une étiquette ne devrait être reconnue comme valide que si la ressource qui y est reliée est sur le ou les hôte(s) déclaré(s). Si aucune restriction d'hôte n'est indiquée, un client PEUT accepter l'étiquette. La priorité donnée aux étiquettes de Type 3 est l'étape cruciale qui permet à un fournisseur de contenu de travailler avec la notion d'une étiquette par défaut pouvant être ignorée localement. Si la ressource contient un lien vers la même ressource qui avait déjà été traitée pour identifier une étiquette de Type 2, il est évident qu'aucun autre traitement n'est nécessaire ; l'étiquette appropriée a déjà été identifiée. Cependant, si un lien mène à une source de données différente de celle qui avait déjà été utilisée pour dériver une étiquette de Type 2, les nouvelles données DEVRAIENT être traitées, pour la simple raison qu'il est possible d'inclure n'importe quel nombre de fichiers de données sur un site, et on peut supposer que celui auquel est relié une ressource donnée est celui que le fournisseur de contenu avait l'intention d'utiliser. Si la ressource ne contient aucun lien, il est évident que les seules informations disponibles sont celles qui étaient disponibles avant que la ressource ne soit extraite. Si plusieurs étiquettes du même Type sont disponibles, le fournisseur de contenu a commis une erreur. Le filtre PEUT utiliser n'importe laquelle d'entre elles, mais, pour des raisons d'efficacité, il utilisera en principe simplement la première trouvée pour un type donné. Acting on the labelAt this stage, the filter has checked whether a label is available, and, if there are multiple labels, has selected the correct one. If there is no label available for a given resource, ICRA recommends that, by default, the filter allows it except when it is an (X)HTML web page. Whether unlabelled (X)HTML web pages are blocked or allowed should be under user control. The reasoning behind this is that if a page is labelled, the author probably intended the label to cover all the elements within the page. They may even be unaware that for each image, external script file and style sheet, a separate request is made to the internet. It is less usual for an image to be accessed directly, i.e. without being displayed within a page or without the user finding the image by following a link from an (X)HTML page. Finally, whilst it is easy for all webmasters to include link tags in an (X)HTML page, linking something like an image to a data source requires the server to be configured. This is generally the reserve of the professional. Rubriques connexes1 Lorsque les règles recommandent qu'une étiquette soit prioritaire sur une autre, ceci ne doit être compris que comme désignant uniquement l'étiquette ICRA ou les composants ICRA d'une étiquette si les descripteurs d'autres vocabulaires sont également présents. Il appartient aux opérateurs des autres systèmes d'étiquetage de faire leurs propres recommandations sur la façon dont leurs descriptions doivent être traitées. 2 « Une étiquette ICRA » peut être constituée d'un ensemble d'étiquettes, en particulier si la ressource étiquetée est un film ou un jeu. En d'autres termes, il peut y avoir une &ea
|
|||||||||||||||